







9 min read

Microsoft Fabric aims to bring together everything from data integration and engineering to warehousing and business intelligence. While Microsoft Fabric simplifies many technical decisions, it doesn’t automatically deliver return on investment. The real value comes from how you implement it and how fast your data turns into business value.
This guide shows how to unlock ROI from Microsoft Fabric using automation, metadata, and a clear data strategy. It also reveals how TimeXtender enhances Fabric’s capabilities, cuts implementation costs, and accelerates time to value.
The ROI Challenge
Adopting Microsoft Fabric is a big step toward a modern and efficient analytics setup. However, implementation doesn't necessary guarantee maximum ROI. Many teams underestimate the effort required to go from raw infrastructure to real business value. Even with Fabric’s unified architecture, organizations still face serious challenges that slow them down and drive up costs:
- Integration Complexity
Despite Fabric's unified approach, organizations still need to migrate and integrate data, build pipelines, define transformations, implement governance, and deliver insights. All of this still takes skilled resources, significant effort, and deep familiarity with the platform. - Resource Requirements
Most teams need a broad mix of talent to fully operationalize Fabric:
- Data engineering for pipeline development
- SQL experts for data warehousing
- Spark developers for scalable processing
- Power BI for visualization and semantic modeling
- Architects for governance and security setup
When these roles aren’t already in place, project timelines stretch and consulting costs climb.
-
Maintenance Burden
In manual Fabric implementations, data teams must write and maintain custom code across multiple services, such as Spark notebooks for data engineering, SQL scripts for warehousing, and Power BI datasets for reporting. This patchwork approach creates silos, increases the chance of errors, and makes the platform harder to scale.
Along with these, insights from FabCon 2025 revealed several common pitfalls that limit MS Fabric’s ROI. One of the most frequent was overloading a single workspace with too many assets. While Fabric offers a unified environment, trying to manage everything from one place often results in performance bottlenecks and governance challenges.
Another recurring theme was the temptation to simply "lift and shift" existing data solutions into Fabric without rethinking how to optimize for the new architecture. This approach brings along legacy inefficiencies and bypasses the benefits Fabric is designed to offer. Similarly, many teams fell into the habit of reusing old data movement patterns, rather than adopting the newer, more efficient methods Fabric makes possible.
Default settings were also a trap. While convenient at first, leaving workloads uncustomized often leads to poor performance and unnecessary spending. And finally, some teams planned too far ahead, trying to design the entire end-state from the beginning, without realizing early wins. This approach delayed the opportunity to prove business value and build internal momentum.
These missteps add up. Without automation and a clear, iterative strategy, organizations often spend months just setting up basic ingestion flows, rewriting transformation logic, and configuring services by hand. That’s time lost, time when stakeholders are still waiting for insights, and costs are still accumulating.
Automation in Fabric Implementation
To maximize ROI with Microsoft Fabric, companies must accelerate deployment, automate repetitive tasks, and simplify governance.
Fabric Metadata-Driven Automation
A Fabric Metadata-Driven Framework (FMD) is an approach where all your data pipelines (ingestion, transformation, loading) are defined by metadata instead of hard-coded logic. Metadata-driven automation uses a declarative approach where you define what needs to happen to the data (business rules, joins, calculations) in an abstract way, and the automation layer takes care of how it's executed in Fabric. This approach offers several advantages:
- End-to-End Pipeline Generation
With FMD, you define what data you need and how it should be transformed at a high level. The framework then automatically generates the necessary code (SQL, Python, Spark) to ingest and transform data, and orchestrates it in the correct sequence. This AI-powered code generation eliminates tedious boilerplate coding and ensures best practices are followed consistently. - Unified Metadata = Consistent Workflows
All pipeline components, from raw data ingestion to final analytics, are driven by one unified metadata model. This guarantees that every step is documented and governed centrally. It also means things like data types, business definitions, and relationships are consistent throughout your Fabric environment. There’s one source of truth for how data flows, which improves quality and trust. - Agility through Configuration
Need to add a new data source or change a business rule? In a metadata-driven setup, you simply update the metadata (via a low-code interface) instead of rewriting big chunks of code. The framework adapts pipelines automatically. This makes your data architecture extremely agile in the face of change, a crucial advantage when business requirements evolve or new data sources appear. - Built-in Governance and Monitoring
Since all aspects of data pipelines are described in metadata, it’s much easier to enable governance features. The FMD approach can provide automatic data lineage (tracking every data element from source to report) and impact analysis when something changes. Real-time monitoring is also made easier, the framework knows every pipeline step and can alert on anomalies or failures proactively. These capabilities would require significant extra effort to implement manually with scripts and standalone tools. - Cost and Resource Optimization
Automation frameworks can intelligently optimize how jobs run on Fabric. For instance, having a dynamic resource orchestration that triggers heavy Spark jobs only when needed and manages execution order for efficiency. It can handle incremental processing and push-down computations to the Fabric engine, reducing redundant data movement. All of this leads to more efficient use of Fabric’s compute capacity, directly reducing runtime costs. Essentially, the FMD acts like an autopilot, making sure you’re not burning money on unoptimized pipelines.
A Fabric Metadata-Driven Framework brings order and intelligence to your Fabric environment. By automating the heavy lifting of data engineering, it not only cuts development time but also ensures your Fabric utilization is efficient.
Impact on ROI
Automation frameworks can dramatically improve ROI by addressing the key challenges of Fabric implementation. According to research shared at FabCon 2025 and supported by Microsoft case studies, metadata-driven automation frameworks like TimeXtender have shown:
- Up to 80% reduction in development time
- A shift to lower-cost roles, with junior engineers editing metadata and freeing up senior staff
- Drastic drops in maintenance effort—schema changes handled via config, not code
| Lever | Detail |
|---|---|
|
OutSystems/KPMG research shows automation halves build cycles; Fabric projects report similar gains when metadata templates replace hand‑coded pipelines. |
|
|
Junior data engineers edit control tables; senior staff review configs, freeing scarce experts for advanced modeling. |
|
|
Centralized metadata feeds Purview, producing consistent lineage and policy enforcement versus disparate ADF/Synapse scripts. |
|
|
Schema drifts or business‑key changes require only a metadata update; no code redeploy, slashing run‑time defects and change‑ticket queues. |
These directly translate into faster time-to-insight, lower staffing costs, and a more agile, compliant data environment.
Metadata-Driven vs. Traditional Tools
When evaluating how to build on Microsoft Fabric, teams often look at familiar tools like dbt or Azure Synapse Pipelines. These frameworks can absolutely work but they come with trade-offs in complexity, cost, and scalability.
Below is a quick comparison:
| Feature Area | TimeXtender (Metadata-Driven) | dbt (SQL-First) | Synapse Pipelines (Traditional) |
|---|---|---|---|
|
Approach |
Drag-and-drop interface + AI automation |
Code-centric SQL + Jinja scripts |
GUI-based workflows with code |
|
Scope |
End-to-end integration, transformation, orchestration, governance |
Focused on transformation only |
Orchestration + basic transformation |
|
Learning Curve |
Moderate — designed for data pros with light coding needs |
High — requires SQL fluency + software practices |
Moderate — easy to start, harder to scale |
|
Metadata & Lineage |
Built-in, full lineage and documentation out of the box |
Partial — limited to dbt-managed models |
Requires Purview or external setup |
|
Agility & Reuse |
One-click deployment; config-based changes; highly reusable logic |
New code needed for new use cases or changes |
Limited logic reuse; manual edits needed |
|
Governance & Quality |
Centralized control; metadata-enforced rules |
User-defined tests only; no built-in governance |
Basic; scripting required for quality checks |
|
TCO |
Higher productivity; fewer tools and engineers required |
Free core, but high engineering effort and tool sprawl |
Included with Fabric, but high ongoing maintenance |
Tools like dbt and Synapse Pipelines offer powerful capabilities but they rely on manual code, scattered governance, and high-skill labor to operate at scale. TimeXtender delivers the same outcomes and often more with less code, smaller teams, faster timelines, and lower long-term cost
That’s why more organizations are embracing metadata-driven platforms to build a data strategy that’s modern and sustainable.
How TimeXtender Unlocks ROI on Fabric
For organizations seeking to maximize their Microsoft Fabric ROI, TimeXtender adds that missing layer to it: automation. Through its intelligent automation, TimeXtender offers a powerful solution that addresses the challenges outlined earlier.
TimeXtender is a holistic data integration and management platform that complements Microsoft Fabric by filling in gaps and automating heavy lifting. It acts as a smart orchestration engine on top of Fabric, helping you ingest, prepare, and deliver business-ready data up to 10× faster, without writing code.
Key Capabilities That Drive ROI
- Low-Code Pipeline Development
TimeXtender provides a drag-and-drop environment for building data pipelines into Fabric. Your team can connect to data sources and define transformations through an intuitive interface, instead of hand-coding pipelines. The platform then automatically generates the underlying code to execute those pipelines within Fabric.
This bridges skill gaps and accelerates development. TimeXtender reports that its automation can cut development costs by 70–80% and deliver data 10× faster than manual coding. - Centralized Metadata Management
TimeXtender centralizes metadata management and governance for your data estate. All business logic and metadata are stored in TimeXtender's unified repository.
This ensures consistent documentation and governance rules as data flows through Microsoft Fabric. TimeXtender's automation layer acts as a guardrail, applying data quality checks, transformations, and access controls uniformly. - Platform-Agnostic Design
Microsoft Fabric replaces Azure Synapse, just as Synapse replaced SQL DW. What happens when the next tool arrives? With TimeXtender’s metadata-driven, you can redirect or extend your pipelines to other storage platforms or cloud services with minimal rework.
This mitigates vendor lock-in concerns by preserving your freedom to choose or change technology. TimeXtender abstracts your data logic away from any specific engine. Whether you're deploying to Microsoft Fabric today, Snowflake next year, or another engine in the future, you preserve your core logic. That’s strategic insurance.
Medallion Support
Microsoft promotes the medallion architecture, organizing data in Bronze, Silver, and Gold layers, as a way to improve trust, traceability, and performance. TimeXtender aligns perfectly with this approach by automating each layer through metadata and low-code logic. That means you get a clean, scalable architecture by default, without hand-coding or over-engineering.
As defined by Microsoft, “the medallion architecture describes a series of data layers that denote the quality of data stored in the lakehouse. The terms bronze (raw), silver (validated), and gold (enriched) describe the quality of data in each of these layers.” In practice, this means you ingest raw data into a Bronze layer, then clean and transform it into a Silver layer, and finally aggregate or model it for business use in the Gold layer. Each step increases the data’s usefulness.
TimeXtender automatically aligns with medallion principles by separating data into an ingestion layer (raw Operational Data Exchange, equivalent to Bronze), a transformation layer (cleansed and modeled data, akin to Silver), and presentation layer (data marts or warehouses for Gold). With a few clicks, you can set up pipelines that ingest raw data into OneLake (Bronze), apply transformation logic to create cleaned data sets (Silver), and publish business-level aggregates to Fabric warehouses or Power BI (Gold). The heavy lifting of creating and scheduling these intermediate steps is handled by the metadata-driven engine. Benefits of this automated medallion approach include:
- Best practices by default
You get a robust multi-layer architecture without needing to manually code the plumbing between layers. The framework ensures raw data is always archived and accessible, transformations are traceable, and gold datasets are always up-to-date with the latest source inputs. - Improved data quality and trust
By systematically moving through Bronze→Silver→Gold, data quality issues are caught and handled in the Silver stage (e.g., applying data quality rules, validations). The result is high-quality Gold data ready for analytics. All these rules and transformations are centrally documented via metadata. - Reduced maintenance effort
If your schema changes or business logic updates, the framework can regenerate the Silver and Gold layer processes automatically, rather than developers having to modify multiple ETL scripts. This keeps the medallion flow resilient to change (tying back to agility and cost savings on maintenance). - Visualization and understanding
Having an explicit layered structure (often visualized in diagrams as above) helps technical and non-technical stakeholders understand the data pipeline. It provides a clear mental model of how raw data becomes refined insight. Such clarity is valuable for governance and for onboarding new team members and it’s essentially provided out-of-the-box by the framework.
For organizations already using TimeXtender, the good news is that adopting Fabric doesn’t mean abandoning your medallion design or re-writing pipelines. Thanks to the unified metadata approach, your existing data logic can be ported into Fabric seamlessly. TimeXtender’s integration with Fabric’s OneLake and Data Warehouse ensures that Bronze, Silver, Gold layers are implemented using Fabric’s storage and compute engines, protecting your previous investment and minimizing migration effort.
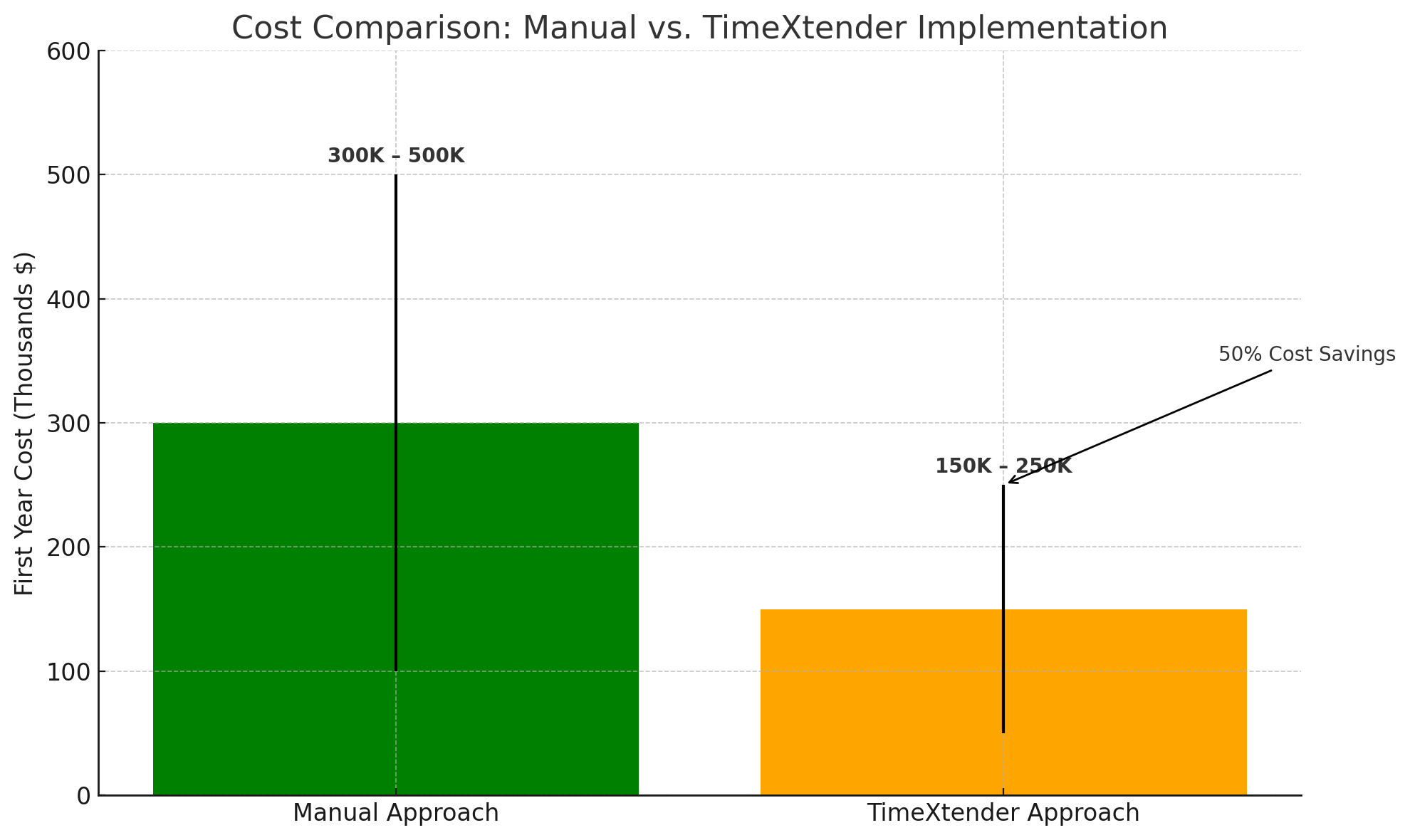
ROI Comparison: Manual vs. Automated
To put the impact of TimeXtender into perspective, let’s compare two scenarios side-by-side: one using Microsoft Fabric alone, and one using TimeXtender’s low-code automation on top of Fabric.
The results speak for themselves:
- Setup time drops from 6 months to 4 weeks
- Engineering effort is reduced by up to 90%
- Estimated first-year costs are cut nearly in half
| Phase | Manual MS Fabric Implementation | MS Fabric + TimeXtender |
|---|---|---|
|
Initial Setup |
3–6 months |
2–4 weeks |
|
Development Time |
500–800 hrs |
50–100 hrs |
|
Required Roles |
Data engineer, Spark dev, SQL dev, BI dev |
Data engineer or analyst |
|
Code Maintenance |
Ongoing |
Automated |
|
Metadata/Lineage |
Manual setup |
Built-in |
|
Governance |
Spread across tools |
Centralized |
|
Flexibility |
Limited to Fabric |
Portable logic |
That’s a savings of up to $350,000 in the first year alone, not including the opportunity cost of delayed insights or the staff time reclaimed by automating maintenance tasks.
For CIOs and data leaders, this is a competitive advantage. You get faster time-to-insight, without sacrificing governance or performance, lower staffing requirements, freeing up your senior engineers for innovation and a future-proof architecture, ready to adapt as tools evolve.
Unlock the Full Potential of Microsoft Fabric with TimeXtender
Building data solutions on Microsoft Fabric doesn’t have to mean navigating complexity, manual coding, or soaring costs. TimeXtender’s holistic, low-code suite is purpose-built to eliminate these barriers, automating everything from data ingestion and transformation to governance and orchestration. By unifying your data stack with intelligent automation and seamless integration, TimeXtender empowers your teams to deliver robust, scalable analytics solutions up to 10x faster and at a fraction of the cost.
Whether you’re looking to streamline data integration, enforce data quality, enrich data, or orchestrate end-to-end workflows, TimeXtender provides the foundation for reliable, future-proof analytics on Microsoft Fabric. And the result is faster time to value, reduced operational risk, and more time to focus on what matters most - turning data into actionable insights that drive your business forward.
Ready to see how TimeXtender can accelerate your Microsoft Fabric journey? Book a demo and experience firsthand how we help you simplify, automate, and execute.
