
4 min read

Taxonomy and Guiding Principles
A guest blog post from Kevin Petrie, VP of Research at Eckerson Group
Humans have always struggled to integrate data. The rise of the abacus 5,000 years ago, punch cards 130 years ago, and the data warehouse in the 1980s each advanced civilization because they combined lots of data, quickly, to help us make decisions.
This blog, the first in a series, describes a taxonomy for data integration to support modern analytics, and recommends guiding principles to make it work across on-premises and cloud environments. As is often the case, people and process matter as much as tools. Data teams must adhere to business goals, standardize processes where they can, and customize where they must. Even while anticipating future requirements, they also must “embrace the old” by maintaining the necessary linkages back to heritage systems that persist. Blog 2 in the series will explore how to migrate your data warehouse to the Azure cloud, and blog 3 will explore how to support machine learning (ML) use cases on Azure.
Let’s start with a definition. In the modern world of computing, data integration means ingesting and transforming data, schema and metadata, in a workflow or “pipeline” that connects sources and targets. Often the sources are operational, and targets are analytical. You need to consolidate previously siloed data into accurate combined views of the business. You also manage those pipelines and control their data integration processes for governance purposes.
Taxonomy
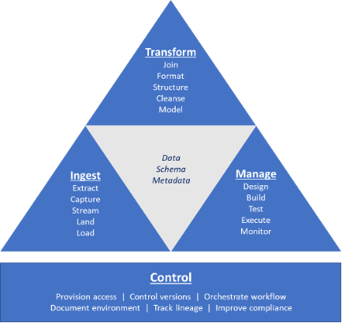
Data integration includes four components: ingestion, transformation, pipeline management, and control. Microsoft’s SQL Server Integration Services (SSIS) and Azure Data Factory (ADF) help data engineers and architects perform these tasks based on commands they enter through either a command line or graphical interface. Mid-sized enterprises, and understaffed data teams within larger enterprises, also can use a tool such as TimeXtender to further automate, streamline, and accelerate these tasks.
- Ingest. You need to extract (i.e., replicate) batches or increments of data (as well as their schema and metadata) from sources that might include on-premises databases such as SQL Server, cloud applications such as Salesforce, or various IoT telemetry sensors. You load those data batches, or stream those increments, to targets such as Azure Synapse Analytics, which combines data warehouse and data lake constructs to support all types of analytics workloads. You also might land them in a staging area for transformation before loading them into the final target.
- Transform. The transformation step plays a critical role in preparing multi-sourced, multi-structured data for analytics. You join, format, and structure data, and even import or create a model that defines how data elements relate to one another. You might map source attributes to target attributes in order to get a consolidated, accurate picture of the business across those interrelated datasets. Transformation includes the critical task of data cleansing, which resolves conflicts, inconsistencies, and redundancies to ensure accuracy.
- Manage. You also need to manage the pipelines that ingest and transform data between sources and targets. You design, develop and test those pipelines to ensure they deliver accurate and timely data. Once you deploy them in production, you monitor, tune and potentially reconfigure the data pipelines to meet service level agreements.
- Control. These pipelines live in complex environments that need oversight. Data engineers and architects must provision access to various stakeholders, control versions of their data sets and pipelines, and orchestrate sequences of analytics tasks as combined workflows. They also must track the lineage of datasets and generate documentation of projects and environments to satisfy compliance requirements.
This diagram illustrates the components of modern data integration.
The sequence of ingestion and transformation tasks might vary, depending on your requirements. Options include traditional data extraction, transformation, and loading (ETL), transformation of data after it is loaded into the target (ELT), or iterative variations such as ETLT and ELTLT.
Guiding Principles
So how do we make this stuff work? Large and midsized enterprises struggle with a history of technical debt when it comes to data integration. Over the years, their data teams tend to hand-craft brittle transformation scripts with little attention to compatibility or documentation. Scripts break when they encounter new data sources, pipelines, or versions of BI tools, forcing them to cancel upgrades or write new code from scratch. Some data teams connect BI tools directly to data sources, which creates silos and bottlenecks.
Here are guiding principles for data integration that keep you on the right track.
- Start and finish with business objectives. Few principles are more self-evident, and more neglected. Data scientists and BI analysts often request data pipelines to support isolated analytics use cases with unproven ROI. Data engineers and architects should filter those project requests based on their alignment with C-level priorities. They also should modernize their pipelines to support the business objectives of reduced cost and improved flexibility. This means implementing automated tools, standardizing processes, and consolidating platforms.
- Standardize where you can. Make your data pipelines as modular and interchangeable as possible. This speeds development, simplifies testing, improves quality, and reduces the effort of maintenance and support. Commercial tools such as TimeXtender help you reduce or even eliminate the manual scripting that is typically required to design, configure, execute, and monitor data pipelines from many sources into SQL Server or Azure Synapse. Their graphical interfaces layer onto SSIS and ADF, guiding users with intuitive prompts and auto-populated fields. Ideally, you can apply roughly the same sequence of drag-and-drop steps to multiple pipelines without manually changing the underlying scripts.
- Customize where you must. Each business has some peculiarities that require a custom approach. For example, ML use cases such as fraud detection, customer recommendations, and preventive maintenance often require custom models, transformation jobs, and integration work. Data engineers should design pipelines that can insert these custom components, operate them, and monitor them with as little additional scripting as possible.
- Look around the corner. Expect to address new use cases next year and each year thereafter. Architect data pipelines, and evaluate data integration tools, based on their ability to support new data types, end points, and workloads in the future without significant reconfiguration. By adopting open data formats and APIs today, you can avoid a costly redesign in the future if you want to incorporate targets or tools outside the Azure ecosystem.
- Embrace the old. Traditional on-premises systems have a knack for living on. A Deloitte and Forrester Consulting survey last year found 91% of US enterprises expected to increase their mainframe footprint in the next 12 months. Many cloud analytics platforms need to continuously ingest operational data from heritage systems like these on premises. You should invest in tools that can extract data from heritage systems without hurting production workloads, then re-format that data for transformation and analysis in your Azure Synapse target.
We have come a long way in our struggle to integrate mountains of data. Now that we have defined our taxonomy and established guiding principles, our next blog will explore how to migrate your data warehouse to the Azure cloud.
If you'd like to learn more about data integration in Microsoft environments, please join Kevin Petrie of Eckerson Group and Joseph Treadwell of TimeXtender for a webinar, The Art and Science of Data Integration for Hybrid Azure Environments. This webinar will be held Jun 16, 2021 02:00 PM Eastern Time. Can't make it then? Please sign up so you will receive access to the recording after the event.
Or read the Eckerson Group Deep Dive Report on Hybrid Cloud Data Integration. (no form to fill out!)